MPI parallelisation enables precise tsunami simulation with inundation in real time
The LEXIS project aims to enable demanding computational workflows and to optimise their building blocks and components. To better respond to the real-time computing requirements in WP6, we added parallelisation via the Message Passing Interface (MPI) to the tsunami simulation code TsunAWI (https://tsunami.awi.de), and made it executable on the LEXIS platform. The modified code shows substantial improvement in terms of quality of the simulation results (more precise) as well as the processing time.
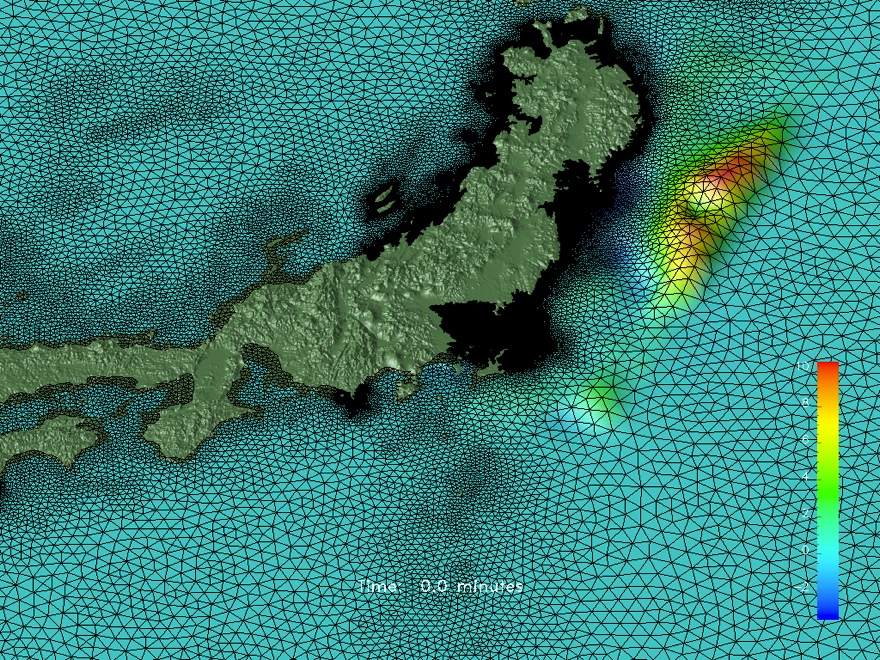
In the past, our focus with TsunAWI has been on pre-computing tsunami scenarios in high resolution, based on the non-linear shallow water equations with flooding and drying. These simulations are of high quality. Their results can serve not only as early warning products based on the wave height at the coast, but also as an input information for risk maps and evacuation planning.
However, without any further optimization, high resolution simulations have been very time-consuming. Till now, real-time computations in case of a tsunamigenic earthquake had to be performed with simpler physical models, without inundation simulation, and at coarse resolution. Precise simulations with TsunAWI at an acceptable processing time, meeting the requirements of an early warning system, has not yet been possible.
LEXIS enabled us to take a great leap! Instead of using 4 – 8 processor cores of a personal computer or 20 – 40 cores of a server based on OpenMP instructions, by adding MPI parallelization to the code, TsunAWI can now use parts of a supercomputer, consisting of many servers (so-called nodes). For example, in LEXIS tests are run on IT4I’s Salomon cluster with more than 1,000 nodes or on LRZ’s Linux Cluster – typical HPC (High-Performance Computing) machines.
By executing the TsunAWI code on these large machines, all processor cores work together to compute the tsunami propagation. We have now adopted the framework of the global ocean model, FESOM (https://fesom.de/), TsunAWI’s big brother, that helps us to distribute the work among processors, dividing a large computational mesh into smaller submeshes. In order to compute the tsunami propagation of a large mesh parallelly, values at the borders of submeshes have to be exchanged, for which different compute nodes communicate with each other using explicit MPI messages. Implementing this in an optimized way involves quite a programming effort, but has two advantages. First, real-time applications can fully exploit the high-performance computing resources. Second, explicit MPI parallelisation allows the programmer to understand speed limitations caused by passing messages. Thus, the overhead time due to the parallelisation can be analyzed and reduced, improving the parallelism efficiency, also for runs on a single server system.
We have obtained the best performance based on a hybrid-parallel approach, where 4 parallel processing “threads” are started via OpenMP, and the rest of the parallelisation occurs via MPI.

The table shows the run-time improvement of the MPI parallel TsunAWI when more cores are used (strong scaling), or when number of cores and problem size are modified (weak scaling). 2-4000 cores can be used by TsunAWI with good efficiency.
With sufficient compute resources at hand, simulation areas can be extended without additional time needed for the simulation. In the past without MPI parallelisation, we had to restrict the TsunAWI simulation to one region of interest, e.g. the city of Padang (Sumatra island), at coarse resolution for fast estimates. By executing the enhanced code on the LEXIS infrastructure, we can now compute the tsunami propagation and inundation for the whole Indonesian Archipelago within just one minute. A simulation for this same area, with its 5000km extent from Sumatra in the West to New Guinea in the East, would have cost us about three hours some years ago.
In addition to the LEXIS project, this effort has been made possible by more people and entities, in particular the North German Supercomputing Alliance (HLRN) and Atos/Bull. We thank Sebastian Krey (GWDG) for optimizing the compute node setup, the Scientific Board of HLRN for granting a consulting project, and Alesja Dammer and John Donner (Atos/Bull) for many hints on code optimization in a hybrid-parallel context.












")





